VMware Aria Operations for Applications (formerly known as Tanzu Observability by Wavefront) performs series matching to identify meaningful pairs of individual time series to operate on. For example, because of implicit series matching in the following operation, the query engine compares metrics for disk reads and disk writes only when they come from the same source and have common point tag values:
ts(~sample.disk.bytes.read) > ts(~sample.disk.bytes.written)
join(...INNER JOIN...) if you need to match up series whose sources and point tags do not correspond exactly.Implicit Series Matching
The query engine performs series matching implicitly when you apply certain operators and functions to two or more ts() expressions, where each expression represents two or more unique metric|source|point tag value tuples. The following operators and functions automatically perform series matching:
- Arithmetic operators (+, -, /, *)
- Boolean operators (and, or)
- Comparison operators (>, <, =, >=, <=, !=)
- Filter functions (highpass, lowpass, min, max)
- Exponential and trigonometric functions
Series Matching Occurs
The following examples show when series matching occurs:
| Query | Result | Reason |
|---|---|---|
| (A,B,C) * (B,C,D) | (B,C) | Only series B and C match up |
| (A,B,C) and (X,Y,Z) | NO DATA | No series match up which results in no data |
| (A,B,C) [>] (A) | (A) | With the second argument being A only there would be no series matching, but the inner join around > forces series matching. As a result, we'll have a join on A only, resulting in 1 series instead of 3. |
Series Matching Does Not Occur
The following examples show when series matching does not occur:
| Query | Result | Reason |
|---|---|---|
| (A,B,C) / 3 | (A,B,C) | The number 3 is a single constant value and is applied to A, B, and C |
| (D) * (A,B,C) | (A,B,C) | D is a single series value and is applied to A, B, and C. |
| (B,D,F) + sum(A,B,C) | (B,D,F) | While B is the only series in both arguments, A, B, and C are aggregated into a single value with sum() and applied to B, D, and F. |
Series Matching Basics
Suppose you enter the following ts() expression:
ts("stats.servers.MemTotal", tag="dc1") - ts("stats.servers.MemFree", tag="east")
The query engine determines which time series match up and subtracts the value for stats.servers.MemTotal from stats.servers.MemFree for each matching series.
Assume that the source tags dc1 and east have three sources that match up (app-3, app-4, app-5), and four sources that don’t (app-1, app-2, app-6, app-7). As a result, the chart displays only data associated with app-3, app-4, and app-5. The data for app-1, app-2, app-6, and app-7 are ignored.
| dc1 | east |
|---|---|
| app-1 | app-3 |
| app-2 | app-4 |
| app-3 | app-5 |
| app-4 | app-6 |
| app-5 | app-7 |
There are cases when you apply functions to expressions, but no series matching occurs. This happens when one of the evaluated ts() expression is a constant value, such as 1, or represents a single time series, such as a single source or aggregated data with no “group by”.
For example, if you replaced tag="east" with source="app-4", then the value associated with app-4 in the second expression at each time slice is subtracted from each represented source in the first expression at each time slice. If you still want series matching to occur in the previous example, then you can wrap the operator or function with strict inner join (i.e. [+]).
Series Matching Example
Here’s an example where you see a message below the query that starts like this:
15 series were not included in all queries (showing up to 5):...

Some of the series are not included in all queries because there was no match.
- Some expressions limit the environment to
env="dev" - Other expressions don’t use the filter.
When part of a query uses a filter, but another part doesn’t, then the whole query uses the filter. In this example, all queries will be limited to
env="dev"
Series Matching with Point Tags
Consider the following ts() query:
ts(disk.space.total, tag="az-1" and env=*) - ts(disk.space.used, tag="az-1" and env=*)
In this example, the env point tag key takes the values "production" and "development". If source app-1 includes the env value "development" in the first ts() call, but includes the env value production in the second ts() call, they do not match up.
Series matching occurs only for exact matches. This also means that if two series have the same source|metric|point tag but one of the series includes an additional point tag that the other series does not have, series matching does not include the series with the additional point tag in the results.
Series Matching with the “by” Construct
In some cases, series matching with point tags results in no data because not all of the tags exist on both sides of the operator. You can use the by construct to perform matching using the element of your choice to get results for those series.
This section explains the concepts using the by construct.
by, you can use join(...INNER JOIN...) if you need to match up series whose point tags do not correspond exactly.Suppose you’re interested in the set of hosts that have a cpu.idle of more than 50 and a build.version equal to 1000. You start with a set of hosts and run the following query:
(ts(cpu.idle) > 50) and (ts(build.version) = 1000)
The following series are returned by the first part of the query, (cpu.idle) > 50:
| Source | Datacenter | Stage |
|---|---|---|
| host-1 | [dc=Oregon] | [stage=prod] |
| host-2 | [dc=Oregon] | [stage=prod] |
| host-3 | [dc=Oregon] | [stage=test] |
| host-1 | [dc=NY] | [stage=prod] |
| host-2 | [dc=NY] | [stage=prod] |
| host-3 | [dc=NY] | [stage=test] |
The following series are returned by the second part of the query, (build.version) = 1000
| Source | Stage |
|---|---|
| host-1 | [stage=prod] |
| host-1 | [stage=dev] |
| host-2 | [stage=prod] |
| host-2 | [stage=dev] |
| host-3 | [stage=test] |
| host-3 | [stage=dev] |
It seems like an operation on these two series should yield a result, but the query with the AND operator above returns NO DATA because the dc tag cannot be matched on both sides of the expression.
In this example, while there is a host-1 on both sides of the operation, the first part of the query maps to two different hosts named host-1. There’s no guidance on which of these 2 hosts to pick, so the system doesn’t pick one.
You can use the by query language keyword to specify the point tag(s) to map by. For the example above, you can expand the query as follows:
(ts(cpu.idle) > 50) and by (stage, source) (ts(build.version) = 10000)
With this addition, the query returns the following 6 series, joined with the elements on the right.
| Series | Joined With |
|---|---|
cpu.idle host="host-1" dc=Oregon stage=prod |
build.version host="host-1" stage=prod |
cpu.idle host="host-2" dc=Oregon stage=prod |
build.version host="host-2" stage=prod |
cpu.idle host="host-3" dc=Oregon stage=test |
build.version host="host-3" stage=test |
cpu.idle host="host-1" dc=ny stage=prod |
build.version host="host-1" stage=prod |
cpu.idle host="host-2" dc=ny stage=prod |
build.version host="host-2" stage=prod |
cpu.idle host="host-3" dc=ny stage=test |
build.version host="host-3" stage=test |
Processing Output Metadata From a Series Match
If you don’t specify an operator in your query, the query engine automatically flips the query to the side with more dimensions. To achieve many-to-one and one-to-many series matching and specify which side of a query metadata to have in your query results, use the groupRight and groupLeft operators.
Automatic Query Flip
Unless you use an operator, such as such as groupRight and groupLeft, the query engine automatically flips the query to have the more detailed side of the join be the driver. In the example above, that is the cpu.idle part of the query.
Series Matching with “groupLeft” and “groupRight” Construct
You can use groupRight and groupLeft operators to achieve many-to-one and one-to-many series matching, similarly to the Many-to-one and one-to-many PromQL vector matches.
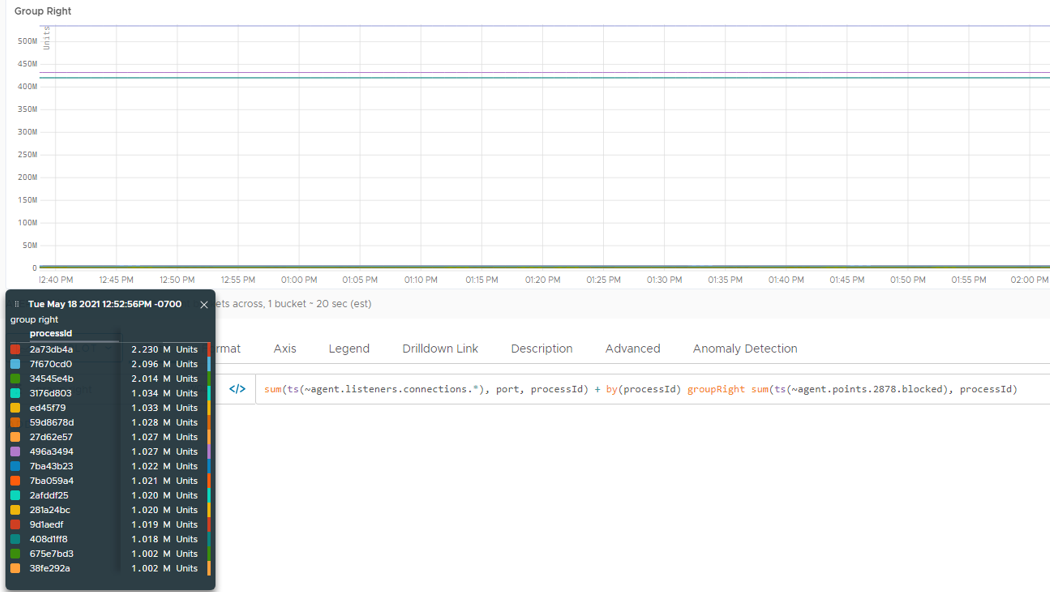
For example, when we use the groupRight operator in the query below, we see results with the processId tag which is on the right side of the operator.
sum(ts(~proxy.listeners.connections.*), port, processId) + by(processId) groupRight sum(ts(~proxy.points.2878.blocked), processId)
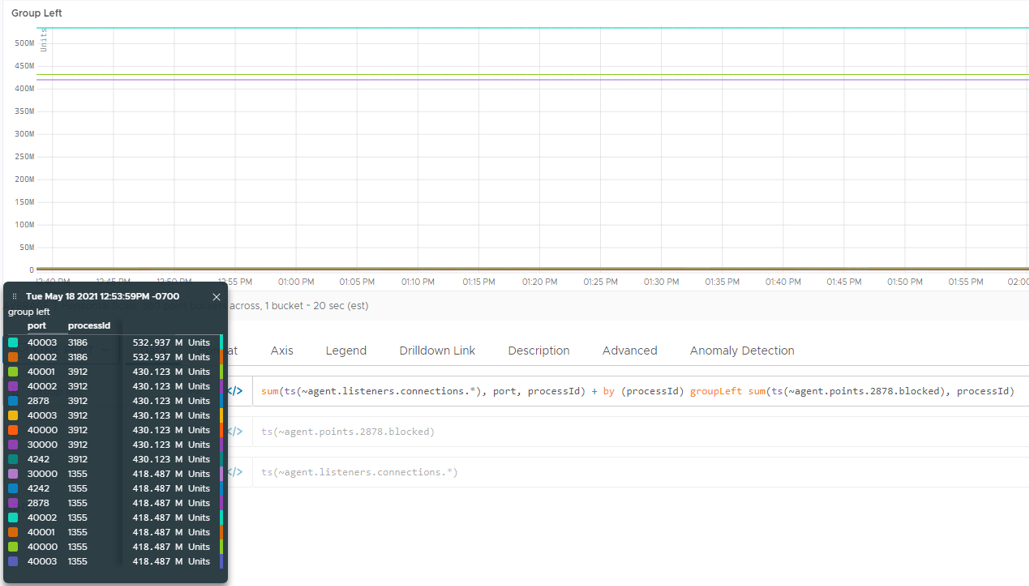
In the example below, we use the groupLeft operator. Therefore, we see results with the port and processId tags, which are on the left side of the operator.
sum(ts(~proxy.listeners.connections.*), port, processId) + by (processId) groupLeft sum(ts(~proxy.points.2878.blocked), processId)